개요
건물에너지 관리 및 점유분석에 대한 3년 데이터셋

- 건물 에너지 소비: 미국에서는 전체 에너지의 약 40%, 전 세계적으로 약 3분의 1을 소비
- 기술 발전의 영향: 에너지 효율, 센서, 고급 제어 기술을 사용면 사용량을 최대 50%까지 줄일 수 있습니다
- 데이터 접근 필요성: 에너지 낭비를 줄이고 건물 운영을 최적화하려면 다양하고 통합된 데이터 세트가 필요
- 현재 문제점
- 적절한 데이터 범위를 갖춘 데이터 세트를 찾는 것은 어렵고 시간 소요.
- 데이터 품질과 문서화(메타데이터 설명)가 부족함.
- 고해상도 데이터의 중요성
- 모든 건물에서 고해상도 데이터를 측정하는 것은 비실용적.
- 고해상도 데이터를 소수의 건물에서 수집하여 공개하는 것이 중요.
- 이러한 데이터 세트는 공정한 알고리즘 비교를 위한 고품질 벤치마크를 제공
데이터 분석

Data 수집
다양하고 통합된 데이터셋 필요
⇒ 모든 데이터 스트림을 소스와 시스템에서 가져와서 influxdb 데이터베이스에 통합

HVAC, 전기, 조명, 점유자 수 , 핵심 온도, Wifi, 날씨 데이터 수집
HVAC, 전기, 조명, 점유자 수 , 핵심 온도, Wifi, 날씨 데이터 수집
Data Set
기간 3년 (2018년 ~ 2020년)
| 측정(들) | 실내 온도 • 전기 • 실내 점유율 |
| 기술 유형 | 온도 센서 • 전기 사용 센서 • 점유 센서 |
| 요인 유형 | 건물 에너지 관리 • HVAC 운영 |
| 샘플 특성 - 환경 | 사무실 건물 |
| 샘플 특성 - 위치 | 캘리포니아주 버클리 |
| 크기 | 약 2.6 GB |
| 비고 | COVID-19 팬데믹이 시작된 |
| 2020년 데이터가 포함 |
Data Set 활용성
- 에너지 벤치마킹 구축
- 부하 형태 분석
- 건물 에너지 예측
- 점유 분석
- 열 시뮬레이션 모델 구축
- 오류 감지 및 진단 (HVAC)
- 거주자 수 예측 및 검증 (WiFi)
데이터 전처리
고해상도 데이터를 수집 , 정리, 공개하는 과정이 필요
⇒ Data Cleaning, Standardization

정제 → 통합 → 축소 → 변환
Data Cleaning
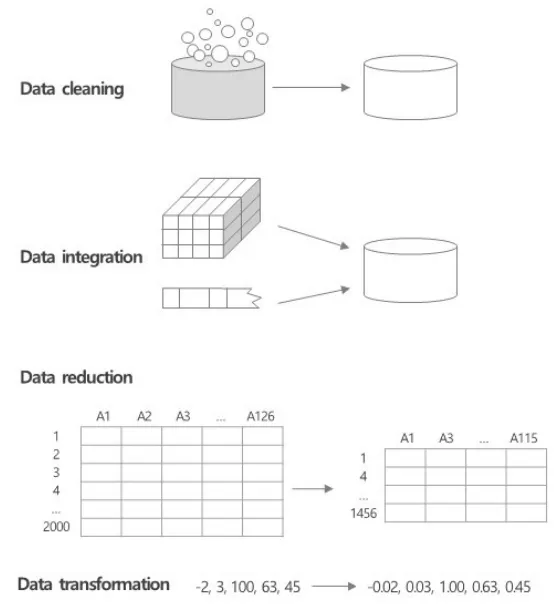
- 중복 데이터 제거
- 관련 없는 데이터
- 특정 분석에 중요한 필드를 식별하고 관련 없는 데이터를 분석에서 제외
- 이상값
- 모델 성능에 큰 영향을 미칠 수 있으므로 이상값을 식별하고 적절한 조치를 결정
- 누락된 데이터
- 누락된 데이터를 플래깅하고 제외 또는 산입
- 구조적 오류
- 데이터가 공통 패턴 또는 규약을 준수하도록 인쇄 오류 및 기타 불일치 문제를 수정
< 데이터를 정리하여 시계열 데이터의 정리된 버전을 생성 >
- 데이터 갭의 길이와 각 데이터 포인트의 샘플링 빈도를 고려
- 큰 갭을 식별하여 삭제, 여러 보간 알고리즘을 사용하여 작은 갭을 채움 (선형 보간법, KNN, MF)
- 비정상적인 값을 부드럽게 하고, 필요한 경우 익명화
(해당 알고리즘들은 이전 문헌에서 건물 전기 및 HVAC 운영의 시계열 데이터 정리에 효과적인 것으로 입증됨)
- 두 개의 메타데이터 모델/파일을 생성
- Brick 모델은 물리적, 논리적 및 가상 자산의 의미 정보와 건물 내의 관계를 제공
- 메타데이터 JSON 파일은 데이터 공유를 간소화하고 데이터 제공자, 사용자 및 애플리케이션 간의 데이터 상호 운용성을 크게 높이는 데 도움
결측치 처리
❔ 결측치 구분 ❔
샘플링 속도 1분에 대한 상한 임계값
小 : 1시간
中 : 10시간
大 : 무제한
샘플링 속도 5~15분에 대한 상한 임계값
小 : 10시간
中 : 1일
大 : 무제한
데이터 갭 크기 방법 설명 절차 장점 단점 발생 상황 대체 가능 알고리즘
| 小 (작은 갭) | 선형 보간법 | 두 점 사이의 값을 직선 방정식을 통해 추정. | 두 데이터 포인트 사이의 임의의 점 x에서의 값 y를 보간. | 계산이 간단하고 빠름. | 비선형적 데이터 패턴 반영 불가. 큰 갭이나 결측값이 많을 경우 정확도 저하. | 데이터 세트 전체에 분산된 작은 데이터 갭 | 이동 평균 (MovingAverage) 급격한 변화 반영 불가 |
| 中 (중간 갭) | KNN | 결측값을 이웃한 K개의 가장 가까운 데이터 포인트의 값으로 추정. | 결측값이 있는 데이터를 선택, 다른 데이터 포인트와의 거리 계산, 가까운 K개의 데이터 선택, 선택된 K개의 데이터 값 평균. | 비선형 데이터에도 적용 가능. 데이터의 지역적 패턴 반영. | 계산 비용이 많이 들 수 있음. K값 선택 중요. 부정확한 결과 초래 가능. | 몇 시간 동안 지속되며 센서의 짧은 정전으로 인해 발생 | 스플라인 보간법 (Spline Interpolation) 계산 복잡도가 높음** |
| 大 (큰 갭) | 행렬 분해 | 대형 행렬을 두 개의 작은 행렬로 분해하여 결측값 예측. 주로 추천 시스템에서 사용. | 원래 데이터 행렬 A를 두 개의 작은 행렬 U와 V로 분해, UV^T 계산하여 결측값 예측. | 대규모 데이터 결측값 효과적 처리. 데이터의 잠재적 구조 반영. | 모델 학습에 시간 소요. 복잡한 수학적 배경 필요. 과적합 문제 발생 가능. | 시스템 또는 센서의 일부가 일시 중지되거나 오류가 발생 | **Kalman 필터 (Kalman Filter) 구현 복잡 초기상태에 민감** |
- 해당 논문 gap 구분 기준 中 : 1시간~1일까지 확장되는 갭
大 : 몇시간에서 최대 며칠까지 이어지는 갭
小 : 몇 개의 연속된 샘플링 주파수에 걸쳐 확장되는 갭
https://www.nature.com/articles/s41597-022-01257-x/tables/5
이상치 처리 (Smooth Anomalies)
- 전기 데이터, 온도 데이터, HVAC 운영 측정, 거주자 측정에서 0보다 작은 값은 이상치로 간주
- 온도 데이터의 경우, 0°C(32°F) 미만 또는 50°C(122°F)보다 큰 값도 이상치로 간주
이상치 값이 데이터 세트에서 연속 샘플링 주파수 미만으로 분산되어 있어 선형 보간이 효과적 - ⇒ 기본 선형 보간 알고리즘을 사용하여 수정
익명화 (Anonymize)
데이터에서 개인 식별 정보를 제거하거나 변형하여 개인의 프라이버시를 보호하는 과정
1. 식별자 제거
직접 식별자: 이름, 주소, 전화번호 등과 같은 명시적인 식별자를 제거.
간접 식별자: 특정 조합으로 개인을 식별할 수 있는 정보(예: 생년월일, 성별, 우편번호 등)를 제거하거나 변형.
2. 데이터 변형
- 데이터 마스킹 (Data Masking): 민감한 정보를 별표(*) 등으로 변환하여 가려서 표시.
- 가명화 (Pseudonymization): 식별자를 무작위 값이나 가명으로 변환하여 직접적인 식별이 불가능하게
- 데이터 범주화 (Data Generalization): 구체적인 값을 일반적인 범주로 변환하여 식별 가능성을 낮춤
- (예: 나이를 10대, 20대, 30대 등으로 범주화).
예시
- Wi-Fi 접속 데이터: 개별 사용자의 접속 기록을 익명화하여 특정 사용자를 식별할 수 없도록 함.
- 예를 들어, 사용자 ID를 무작위로 변환하거나 접속 시간을 집계하여 총 접속 수만 기록.
- 거주자 수 데이터: 특정 시간대의 거주자 수를 집계하여 개인을 식별할 수 없도록 함.
- *_밑줄로 논문 외적인 내용을 표시하였습니다.*
데이터 표준화
Brick Model


표준화된 메타데이터 스키마: 건물의 센서, 장비, 시스템 등의 자산을 표준화된 형식으로 표현.
• isPointOf: 특정 센서나 장치가 더 큰 단위(건물, 층, 구역 등)의 일부임을 나타냄.
• isPartOf: 더 큰 단위가 특정 건물의 일부임을 나타냄.
• hasPoint: 특정 구역이나 장치에 포함된 센서나 설정값을 나타냄.
• hasLocation: 특정 센서가 특정 위치에 있음을 나타냄.
• feeds: 특정 장치나 구역이 다른 장치나 구역에 데이터를 제공함을 나타냄.
• isFedBy: 특정 장치나 구역이 다른 장치나 구역으로부터 데이터를 받음을 나타냄.
❗ 아직 개발 중이며, 특화된 소프트웨어 도구가 필요함.
- 소프트웨어 tool 예시
- Graph Database Integrations
- Telegraf (with InfluxDB)
- Grafana
- Node-RED
- **1. Brick Builder, Brick Validator, Brick Inference Engine**
- 국내 사용 사례
- https://www.ksesjournal.co.kr/articles/xml/NQ0Z/
Data Set의 Brick Model
Metadata JSON File

- 구성 요소데이터 관계: 데이터 항목 간의 관계(예: 부모-자식 관계).⇒ 데이터 관리, 검색, 이해를 돕기 위해 사용
- 기타 메타데이터: 데이터 출처, 생성 시간, 갱신 주기 등.
- 데이터 속성: 각 데이터 항목의 속성(예: 이름, 타입, 단위 등).
⚠️ 데이터 정규화와의 차이점
• 데이터 표준화 (Standardization):
• 목적: 데이터를 공통된 형식과 단위로 변환하여 일관성을 유지하고 비교 및 결합을 쉽게 하기 위함.
• 방법: 주로 평균이 0이고 표준편차가 1이 되도록 데이터를 변환 (z-score 표준화).
• 데이터 정규화 (Normalization):
• 목적: 데이터를 일정한 범위로 변환하여 분석 및 모델링의 효율성을 높이기 위함.
• 방법: 주로 [0, 1] 범위로 데이터를 변환 (Min-Max 정규화).
표준화는 주로 데이터의 스케일을 맞추고 일관성을 유지하는 데 중점을 두며, 정규화는 데이터의 범위를 일정하게 조정하여 분석의 효율성을 높입니다.
Brick Model과 메타데이터 JSON 파일은 이러한 표준화 과정을 지원하는 중요한 도구입니다.
# 코드는 블로그 상에서는 생략. 노션에만 유지.
요약
BEMS 관련 전처리에 유용한 알고리즘 및 표준화 모델 파악
추가적인 연구 자료로서의 Data Set 활용
🙏🏻 관련해서 Python을 통한 데이터분석 공부중입니다.
추가로 공부에 참고할 자료가 있다면 공유 요청드립니다.
- 관련링크Brick SchemaDataSethttps://github.com/LBNL-ETA/Data-Cleaning
- https://www.elastic.co/kr/blog/found-elasticsearch-as-nosql
- Brick TTL Viewer
- 논문
- 참고링크https://wesmckinney.com/book/data-cleaning#data-preparation-conclusions
- https://www.coursera.org/learn/foundations-data-korean/lecture/JjA1f/deiteo-bunseogyi-6dangye
- 건물 에너지 관리와 관련된 다양한 도구와 스키마를 비교 (데이터 범주, 관계, 유연성 및 확장성..
etc)도구 이름 전체 이름 주요 유지 관리자 간단한 설명 참조 링크


