
InfluxDB란?
시계열 데이터(Time Series Data)를 저장하고 관리하는 데 최적화된 오픈소스 데이터베이스
Purpose-built for real-time with proven performance at scale
라고 공식 문서에서 소개하고 있다.
시계열 데이터는 제조, 에너지, IOT, Aerospace등의 분야에서 넓게 사용되고 있기에,
InfluxDB의 역할이 커지고 있다고 생각한다.
Python, C#, JS등 프로그래밍 언어에서도 통합하여 사용할 수 있다.
Get started with InfluxDB | InfluxDB OSS v2 Documentation
Thank you for your feedback! Let us know what we can do better:
docs.influxdata.com
InfluxDB 공식 홈페이지의 Get-started를 진행해보고자 한다.
Set up InfluxDB
InfluxData Downloads
Register your download Get access to the new InfluxDB Open Source Software Onboarding Guide, and product updates.
www.influxdata.com
docker가 아닌 방식으로 다운 받고 싶다면, 위 사이트에 접속 후
version과 platform을 선택하면 밑에 명령어가 나오는데, 이를 터미널에서 실행시켜주자 !
필자는 docker에서 다운받아 진행하였다.
docker --version
docker pull influxdb
docker run -d --name=influxdb -p 8086:8086 influxdb
http://localhost:8086 에서 실행중임을 확인해 볼 수 있다.
Username, Password, Initial Organization Name, Initial Bucket Name을 설정해주면
이제 본격적으로 influxdb를 사용할 수 있다!
All access token 생성 및 bucket 생성 후 ,
CLI를 통해 버킷을 확인해보고자 했다.

그러나 org ID나 name을 작성해달라는 에러메세지를 받았고,
docker exec -it -u root influxdb influx org list --token {token}
token값을 포함한 명령어를 통해 ID와 Name값을 확인해 볼 수 있었다.
docker exec -it influxdb influx bucket list --org-id {id} --token {token}그 후 ID 와 token 정보를 포함한 명령어를 통해

정상적인 출력을 확인해 볼 수 있었다!!
Write data
InfluxDB에서 어떤 작업들을 수행하는 방식에는
InfluxDB UI, CLI, API 이렇게 3가지를 많이 사용한다.
UI를 기반으로 데이터를 넣어보기에 앞서, InfluxDB에 쓰여지는 데이터의 형식에 대해 알아보자.
Line protocol
텍스트 기반 형식인 라인 프로토콜을 사용해 데이터 포인트를 작성한다.
// Syntax
<measurement>[,<tag_key>=<tag_value>[,<tag_key>=<tag_value>]] <field_key>=<field_value>[,<field_key>=<field_value>] [<timestamp>]
// Example
myMeasurement,tag1=value1,tag2=value2 fieldKey="fieldValue" 1556813561098000000요소로는 측정, 태그 세트, 필드 세트, 타임스탬프가 존재한다.
- Measurement : 대소문자를 구분하여 문자열로 작성. 무엇을 측정하는지에 대한 이름을 작성
- Tag set : key-value의 형식이며, 둘 다 문자열로 구성. 대소문자 구분 및 태그 사이는 쉼표로 구분 (optional)
- Field set : key-value의 형식이며, 키 값으로는 문자열, value로는 float, integer,UInteger, String, Boolean이 가능하다. 문자열 value의 경우는 큰따옴표 " " 로 감싸준다.
- Timestamp : optional 하며, 기본적으로 host machine의 UTC를 사용한다.
데이터 포인트에 값이 수신되지 않은 시간을 포함하도록 하려면 타임스탬프를 포함해야 한다.
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1641027600InfluxDB UI에서 Load Data -> BUCKETS -> ADD Data -> Line Protocol을 통해 직접 위와 같은 데이터를 넣어보았다.
집의 거실/주방에 대해 온도, 습도, 일산화탄소의 농도를 측정한 값을 timestamp를 포함하여 넣어주었다
influx write \
--bucket get-started \
--precision s "
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000CLI를 통해 데이터를 삽입하고 싶다면, 위와 같은 방식을 사용할 수 있다.
Query data
시계열 데이터를 쿼리하는데 사용할 수 있는 두 가지 언어에 대해 살펴보자.
- Flux : InfluxDB및 기타 데이터 소스에서 데이터를 쿼리하고 처리하도록 설계된 함수형 스크립트 언어이다.
- InfluxQL : InfluxDB에서 시계열 데이터를 쿼리하도록 설계된 SQL과 유사한 쿼리 언어이다.
Flux가 InfluxDB 2.x에서 새로 도입된 쿼리 언어로, 보다 유연하고 강력한 데이터 처리 기능을 제공하기에,
필자는 Flux를 중점적으로 사용하도록 하겠다.
InfluxQL도 여전히 2.x에서 지원해주고 있기에, 간단한 쿼리를 빠르게 실행하고자 한다면 고려할 수 있을 것이다.
Flux로 InfluxDB를 쿼리할때에는 주로 3가지 함수를 사용한다.
- from () : 쿼리를 실행할 InfluxDB Bucket을 설정한다.
- range () : 시간 경계에 따라 데이터를 필터링한다.
- filter () : 열 값을 기준으로 데이터를 필터링한다.
해당 함수들을 Pipe-forward 연산자 |> 을 통하여 연결해 사용할 수 있다.
from(bucket: "get-started")
|> range(start: 2022-01-01T08:00:00Z, stop: 2022-01-01T20:00:01Z)
|> filter(fn: (r) => r._measurement == "home")
|> filter(fn: (r) => r._field== "co" or r._field == "hum" or r._field == "temp")r을 속성으로 하여 각 column에 접근할 수 있다.
InfluxDB UI를 통해 아까 넣었던 데이터를 직접 확인해 보았다.
Query Builder를 사용할 수도 있고, 필자는 위에서 작성하였던 Script를 직접 넣어보았다.
Data Explorer 창에서 수행이 가능하다.
*Query Builder를 사용하려는데, Filter의 값이 보이지 않는다면, 우측 Time range를 설정해보자.
Past 1h이 기본값으로 설정되어있는데, 우리가 넣어준 데이터는 2022:01:01:17:00~2022:01:02:05:00의 데이터이기에, Custom the Range를 통해 설정해주어야 한다.


Get started processing data
transforming, aggregating, downsampling, alerting on data등의 작업이 가능하다.
대부분의 데이터 처리 작업은 Query Builder가 아닌 Script Editor를 사용하여야 한다.
- Remap or assign values in your data : map ()
map 함수의 자세한 사용법 : https://docs.influxdata.com/flux/v0/stdlib/universe/map/ - Group data : group ()
- Aggregate functions : mean () , count ()
- Selector functions : first( ), last(), max()
- Pivot data into a relational schema : pviot ( )
- Downsample data : aggregateWindow()
- Automate processing with InfluxDB tasks : to ( )
기존 SQL과 크게 다른 점은 없기에, 깊이 설명하지 않겠다.
from(bucket: "get-started")
|> range(start: 2021-12-31T00:00:00Z, stop: 2022-01-01T00:00:00Z) // 주어진 timestamp에 맞는 데이터 범위 선택
|> filter(fn: (r) => r._measurement == "home" and r.room == "Living Room") // 측정값과 방 이름으로 필터링
|> map(fn: (r) => ({ r with temp_f: r._value * 9 / 5 + 32 })) // 온도를 화씨로 변환 (섭씨에서 화씨로)
|> group(columns: ["room"]) // 방 이름 기준으로 그룹화
|> aggregateWindow(every: 1h, fn: mean, createEmpty: false) // 1시간 간격으로 평균값 다운샘플링
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value") // 데이터를 피벗하여 테이블 형식으로 변환
|> yield(name: "processed_data") // 결과 출력
Get started visualizing data
InfluxDB UI나, Chronograf, Grafana등을 시각화하는데 사용할 수 있다.
Dashboards 탭에서 새로 대시보드를 생성하고, cell을 추가하여 화면을 구상해볼 수 있다.
Data Explorer에서 원하는 쿼리를 통해 시각화 한 후,

우측 상단의 save as를 통해 만들어 놓은 대시보드에 셀로서 추가할 수 있다.
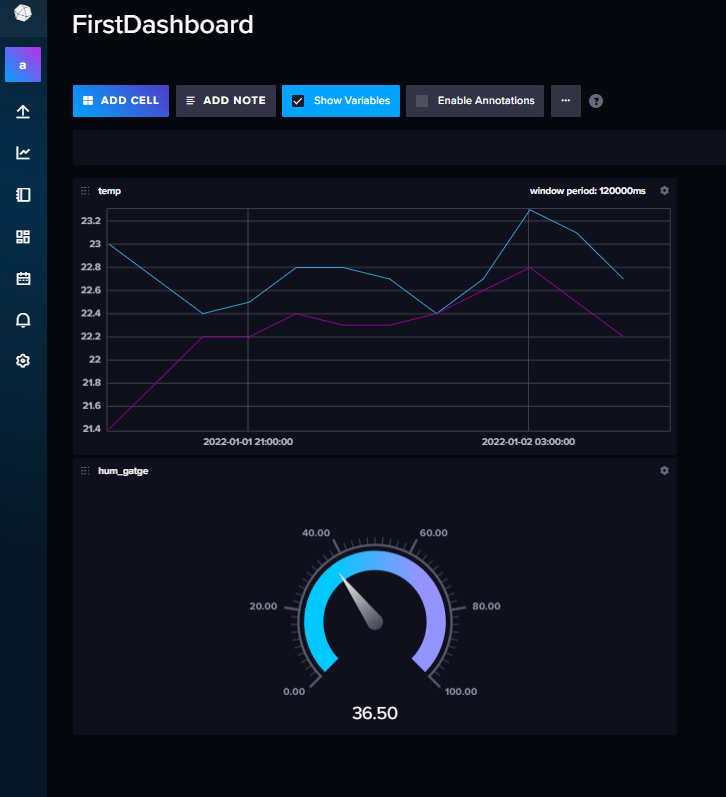
템플릿을 json형식으로 다운받을 수 있다.
- v.timeRangeStart
- v.timeRangeStop
- v.windowPeriod
Flux 쿼리에서 사용되는 프리셋 변수들로, 주로 시간 범위를 설정하거나 자동화된 데이터 처리 시 활용
사용자 정의 변수 또한 설정->변수를 통해 만들 수 있다.
from(bucket: "my_bucket")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> aggregateWindow(every: v.windowPeriod, fn: mean)
|> yield(name: "mean_temperature")데이터의 시작과 끝 시간, 시간 간격등을 변수로 바로 지정해줄 수 있다.
추후 Node-Red라는 툴과 InfluxDB를 함께 사용해볼 예정이다.
InfluxDB | Real-time insights at any scale | InfluxData
Manage all types of time series data in a single, purpose-built database. Optimized for speed in any environment in the cloud, on-premises, or at the edge.
www.influxdata.com